Introduction to Entity Framework Extensions library

I can safely say that about 90% of .NET developers (myself included) love and use Entity Framework in their applications. It’s an elegant, productive Object-Relational Mapper (ORM) that lets us interact with databases using C# objects and LINQ queries instead of writing raw SQL.
However, there’s a “hidden” bottleneck in every data-intensive application: the moment you need to handle bulk data.
Let's dive deeper into the underlying problem with SaveChanges().
The problem
When you try to insert, update, or delete a large number of entities (5,000+ records) using the standard EF approach, you eventually hit a wall. Why?
Because of two issues:
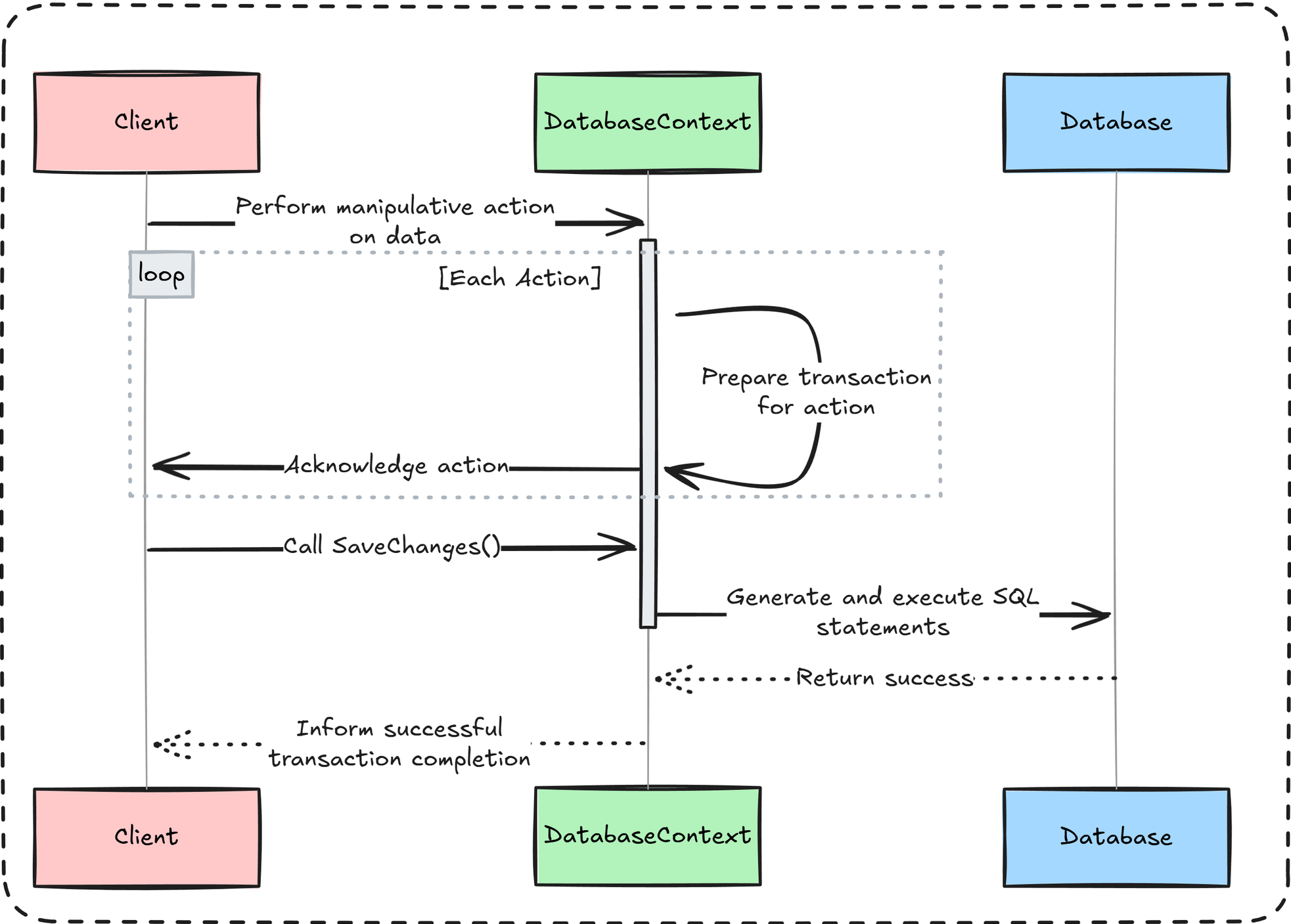
- Excessive database round-trips: Every data manipulation operation is transactional, and when
SaveChanges()is called, EF generates a corresponding SQL statement for each entity. One action = one statement.
So if you try to insert, update, or delete 5,000 records at once, you’ll end up with 5,000 individual statements — which is far from performant.
- Resources overload: Change tracking is resource-intensive.
When you add thousands of entities, the context has to monitor every property of every entity, consuming significant memory and CPU cycles.- Memory overhead -> For each entity EF stores:
- Original values
- Current values
- Tracking metadata(state information, relationship data)
- CPU cycles -> EF must constantly:
- Detect changes by comparing current values to snapshots
- Maintain navigation properties
- Track entity states
- Memory overhead -> For each entity EF stores:
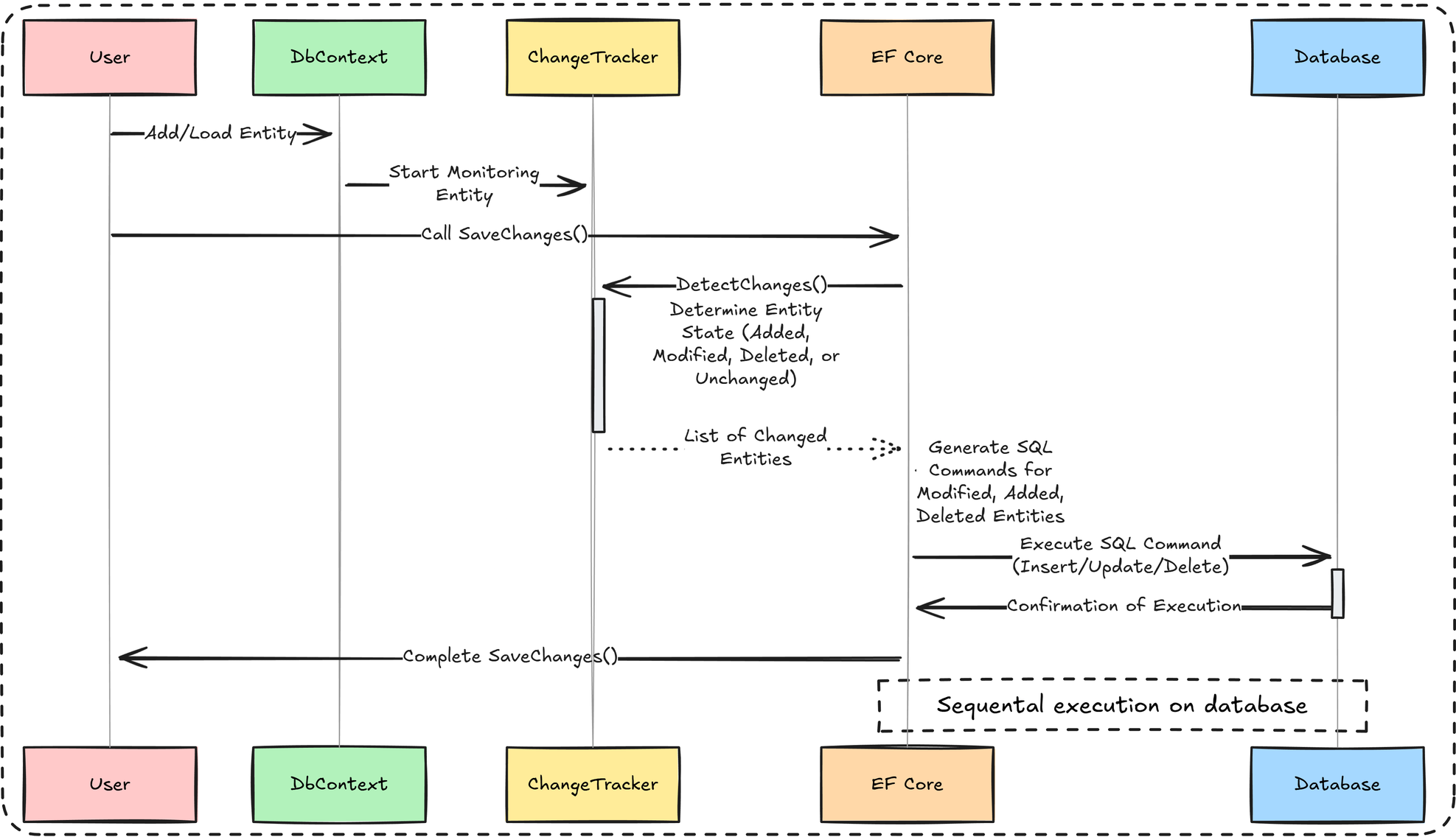
And the change tracker works like this:
- Tracking: When entity is added to DbContext, the ChangeTracker begins monitoring it.
- Detection: When
SaveChanges()is called, EF first runs theDetectChanges()mechanism. This process scans all tracked entities to determine their current state by comparing their current property values with the original snapshots. - SQL generation: For every entity identified as Modified, Added, or Deleted, EF generates a separate SQL command (
INSERT,UPDATE, orDELETE). - Execution: These commands are executed sequentially against the database, each in its own round-trip.
And this is the perfect moment to introduce the solution to this problem: Entity Framework Extensions.
What is Entity Framework Extensions?
It’s a .NET library focused on high-performance bulk operations.
It’s not a replacement for EF Core—they complement each other.
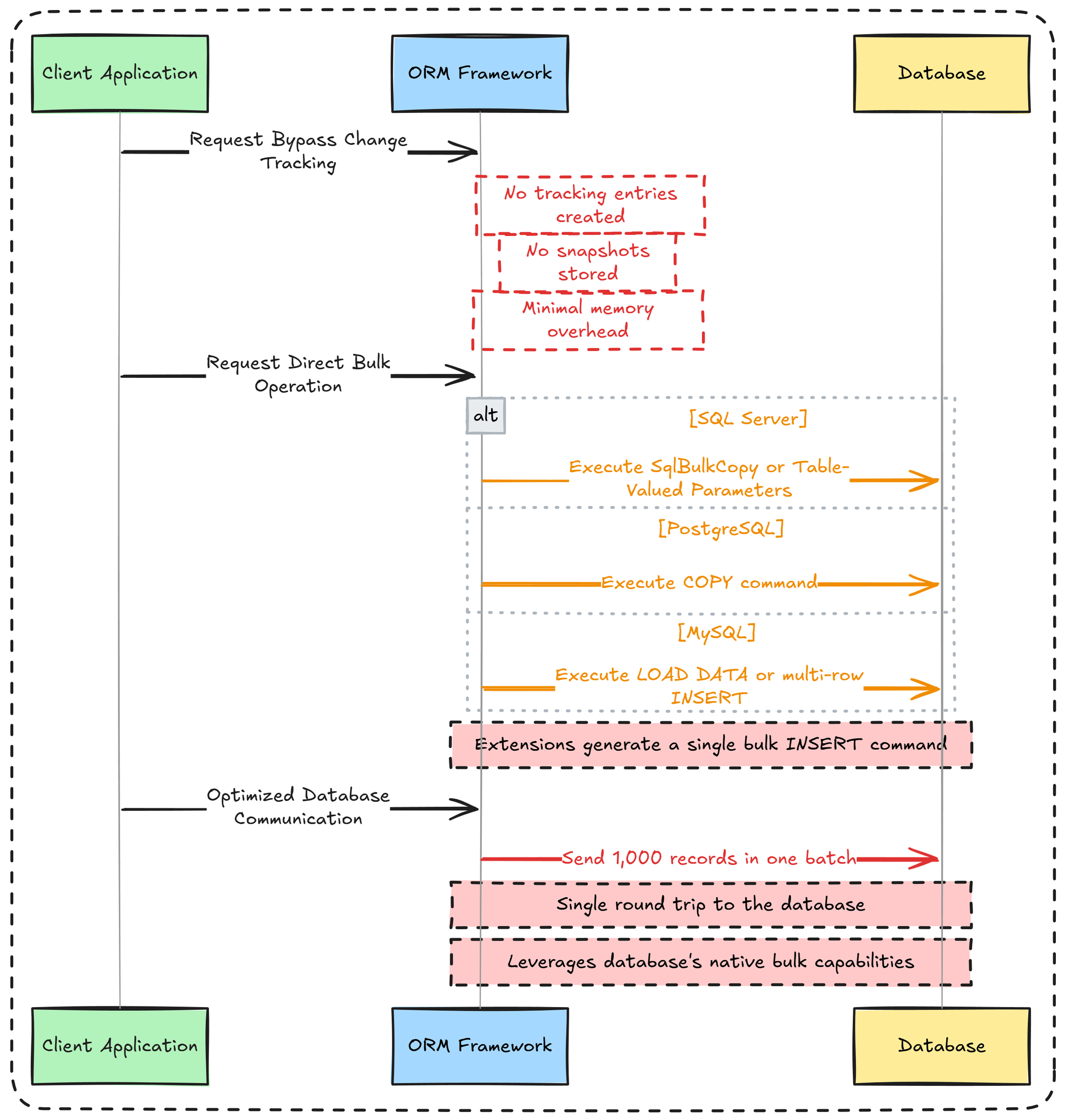
As you can see in the image above, there’s no “magic” behind the scenes.
In the first step, EF Extensions does not rely on the ChangeTracker; instead it uses EF’s metadata model to determine table names, identity columns, primary keys, etc. This operation has no memory cost because the metadata is cached.
The second step converts entities into a format optimized for bulk database operations for the target database (e.g. COPY from PostgreSQL or SqlBulkCopy for SQL Server).
The third step executes the bulk operation transactionally in a single command. Everything unnecessary is stripped away, and the heavy lifting is handled by native bulk-loading mechanisms that move data directly from C# objects to the database.
Enough theory - let’s code!
Entity Framework Extensions in action
Setup
To follow along, you will need:
- Preferred IDE(mine is Visual Studio), but you can also use .NET Fiddle.
- Latest .NET version
- A database provider — since this library supports almost every provider, I’ll be using PostgreSQL.
Also, add the following NuGet packages to your project:
- Npgsql.EntityFrameworkCore.PostgreSQL
- Microsoft.EntityFrameworkCore.Relational
- Microsoft.EntityFrameworkCore.Design
- Bogus
- Z.EntityFramework.Extensions.EFCore
public class Order
{
public int Id { get; set; }
public string CustomerName { get; set; } = string.Empty;
public DateTime OrderDate { get; set; } = DateTime.UtcNow;
public decimal TotalAmount { get; set; }
public string Status { get; set; } = "Pending";
public ICollection<OrderItem> OrderItems { get; set; } = (List<OrderItem>)[];
}
Order.cs
Let's start with: defining entities, database setup, and creating a fake data generator.
public class OrderItem
{
public int Id { get; set; }
public int OrderId { get; set; }
public string ProductName { get; set; } = string.Empty;
public int Quantity { get; set; }
public decimal UnitPrice { get; set; }
public decimal TotalPrice { get; set; }
public Order Order { get; set; } = null!;
}OrderItem.cs
public class AppDbContext : DbContext
{
public AppDbContext(DbContextOptions<AppDbContext> options) : base(options) { }
public DbSet<Order> Orders => Set<Order>();
public DbSet<OrderItem> OrderItems => Set<OrderItem>();
}AppDbContext.cs
var builder = WebApplication.CreateBuilder(args);
builder.Services.AddOpenApi();
builder.Services.AddDbContext<AppDbContext>(options => options.UseNpgsql("Host=localhost;Database=EFE_DB;Username=postgres;Password=admin"));
var app = builder.Build();
if (app.Environment.IsDevelopment())
{
app.MapOpenApi();
}
app.UseHttpsRedirection();
app.Run();Program.cs
public class FakeDataGenerator
{
public static List<Order> PrepareOrders(int count)
{
var orderIdCounter = 0;
var orderItemIdCounter = 0;
var orderItemFaker = new Faker<OrderItem>()
.RuleFor(oi => oi.Id, _ => Interlocked.Increment(ref orderItemIdCounter))
.RuleFor(oi => oi.ProductName, f => f.Commerce.ProductName())
.RuleFor(oi => oi.Quantity, f => f.Random.Int(1, 10))
.RuleFor(oi => oi.UnitPrice, f =>
{
var price = f.Random.Decimal(5.00m, 500.00m);
return Math.Round(price, 2, MidpointRounding.AwayFromZero);
})
.RuleFor(oi => oi.TotalPrice, (f, oi) => oi.Quantity * oi.UnitPrice);
var orderFaker = new Faker<Order>()
.RuleFor(o => o.Id, _ => Interlocked.Increment(ref orderIdCounter))
.RuleFor(o => o.CustomerName, f => f.Person.FullName)
.RuleFor(o => o.OrderDate, f => f.Date.RecentOffset(365).UtcDateTime)
.RuleFor(o => o.Status, f => f.PickRandom("Pending", "Processing", "Completed", "Cancelled"))
.RuleFor(o => o.OrderItems, f =>
{
var itemCount = f.Random.Int(1, 5);
var items = orderItemFaker.Generate(itemCount);
return items;
})
.RuleFor(o => o.TotalAmount, (f, o) => o.OrderItems.Sum(oi => oi.TotalPrice));
var orders = orderFaker.Generate(count);
foreach (var order in orders)
{
foreach (var item in order.OrderItems)
{
item.OrderId = order.Id;
}
}
return orders;
}
}FakeDataGenerator.cs
You're ready to start leveraging bulk operations.
Bulk insert
With one line of code you are able to add thousand of record in just one method.
app.MapPost("/api/v1/insert", async (AppDbContext db) =>
{
var orders = FakeDataGenerator.PrepareOrders(10_000);
var options = new Action<BulkOperation<Order>>(opt =>
{
opt.IncludeGraph = true;
opt.InsertIfNotExists = true;
opt.BatchSize = 1000;
});
await db.BulkInsertAsync(orders, options);
return Results.Ok(new
{
message = "Inserted 10000 orders",
count = orders.Count
});
});Program.cs
I also added some additional option to the method, like:
- IncludeGraph - inserts parent entities AND all their related child entities in a single operation
- InsertIfNotExists - only inserts entities that don't already exist in the database. It checks for duplicates based on a defined key and skips any rows that match.
- BatchSize - controls how many rows are inserted in each database round-trip.
These are just a few examples; you can view the complete list here.
For even better performance, use the BulkInsertOptimized method.
app.MapPost("/api/v1/optimized-insert", async (AppDbContext db) =>
{
var orders = FakeDataGenerator.PrepareOrders(10_000);
await db.BulkInsertOptimized(orders, options);
return Results.Ok(new
{
message = "Inserted 10000 orders in optimized way",
count = orders.Count
});
});Program.cs
The two key differences between this method and BulkInsert are as follows:
- The
AutoMapOutputDirectionflag, which instructs the database not to return any values (such as identity keys) after the query is executed. - The return type. This method returns a
BulkOptimizedAnalysisclass, which provides hints and recommendations for better performance.
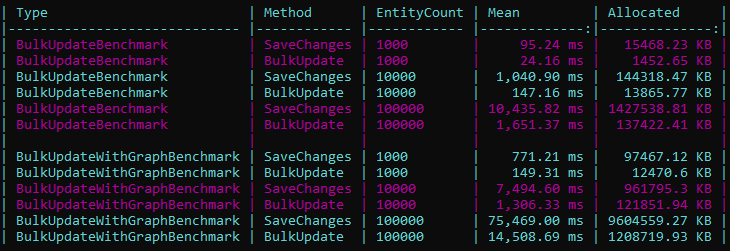
You can see the performance benchmarks for these insert operations below:

Bulk update
The idea is the same as BulkInsert, but here an update is performed.
app.MapPost("/api/v1/update", async (AppDbContext db) =>
{
var orders = await db.Orders.Take(100).ToListAsync();
foreach (var order in orders)
{
order.Status = "Approved";
order.TotalAmount *= 10;
}
await db.BulkUpdateAsync(orders);
return Results.Ok(new
{
message = "Updated 100 orders",
count = orders.Count
});
});Program.cs
Key benefits include:
- Full control over the update behavior
- Avoiding loading entities into memory
- Extensive flexibility with hundreds of options
- Exceptional speed
Bulk delete
The primary advantage is the ability to perform bulk deletions without the need to pre-fetch entities from the database, all through a single method call.
app.MapDelete("/api/v1/delete", async (AppDbContext db) =>
{
var orders = await db.Orders.Take(100).ToListAsync();
await db.BulkDeleteAsync(orders);
return Results.Ok(new
{
message = "Deleted 100 orders",
count = orders.Count
});
});Program.cs
This method provides a feature set consistent with bulk updates, including extensive configuration options and substantial performance improvements.
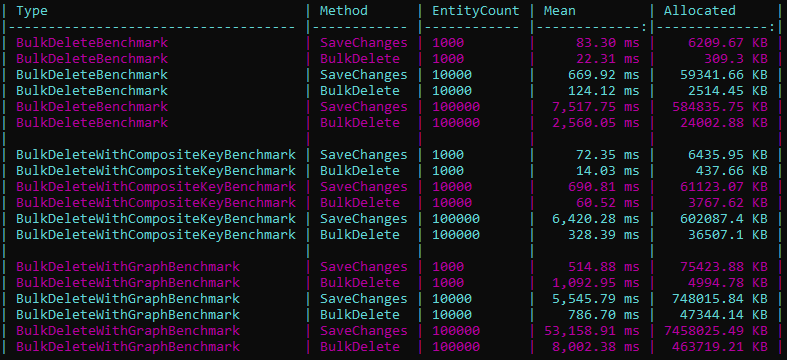
Beyond the basics
Entity Framework Extensions includes more than just Insert, Update, and Delete methods. There are several others that you may find useful.
Bulk merge
The "Add or Update" operation works as follows:
- Update existing rows that match the entity key.
- Insert new rows for records that don't exist.
app.MapPost("/api/v1/merge", async (AppDbContext db) =>
{
var orders = FakeDataGenerator.PrepareOrders(1000);
await db.BulkMergeAsync(orders);
var totalCount = await db.Orders.CountAsync();
return Results.Ok(new
{
message = "Upserted 1000 orders",
count = totalCount
});
});Program.cs
This method replaces multiple SELECT, INSERT, and UPDATE queries with a single, high-performance MERGE command, which can be extended with various options.
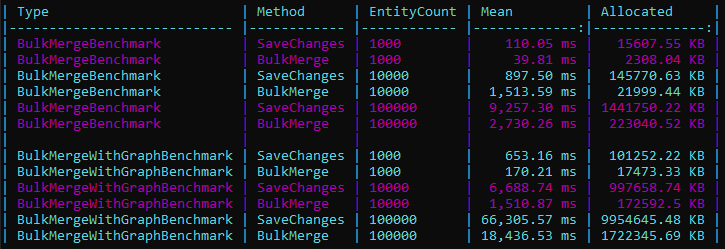
Bulk synchronize
This is an "all-in-one" method because it handles everything in a single operation:
- Rows that match the entity key are updated.
- Rows that exist in the source but not in the database are inserted.
- Rows that exist in the database but not in the source are deleted.
app.MapPost("/api/v1/synchronize", async (AppDbContext db) =>
{
var products = FakeDataGenerator.PrepareOrders(50);
var options = new Action<BulkOperation<Order>>(options =>
{
options.ColumnSynchronizeDeleteKeySubsetExpression = p => p.OrderItems;
options.SynchronizeSoftDeleteFormula = "\"IsActive\" = false";
});
await db.BulkSynchronizeAsync(products, options);
var totalCount = await db.Orders.CountAsync();
return Results.Ok(new
{
message = "Synchronized products - mirrored source list to database",
totalInDb = totalCount,
note = "Orders not in the list were deleted"
});
});Program.cs
Characteristic options for this method include:
ColumnSynchronizeDeleteKeySubsetExpression: Synchronizes a table subset instead of the whole table.SynchronizeSoftDeleteFormula: Marks rows as deleted instead of permanent removal.
BulkSynchronize is a no-op for an empty list. This is vital when using
ColumnSynchronizeDeleteKeySubsetExpression, as a subset cannot be determined without specific items.Now, let's look beyond the performance benefits this method offers.

BulkSaveChanges
How could you not optimize the most critical method in EF Core for maximum performance?
app.MapPost("/api/v1/save-changes", async (AppDbContext db) =>
{
var newCustomers = FakeDataGenerator.PrepareOrders(50);
db.Orders.AddRange(newCustomers);
var existingCustomers = await db.Orders.Take(50).ToListAsync();
existingCustomers.ForEach(c => c.TotalAmount *= 10);
var toDelete = await db.Orders.Skip(100).Take(20).ToListAsync();
db.Orders.RemoveRange(toDelete);
await db.BulkSaveChangesAsync();
return Results.Ok(new
{
message = "BulkSaveChanges processed Add, Update, and Delete",
added = 50,
updated = 50,
deleted = 20
});
});Program.cs
BulkSaveChanges mirrors the SaveChanges method but uses bulk operations for all ChangeTracker entries (Added, Modified, Deleted) to significantly boost performance.
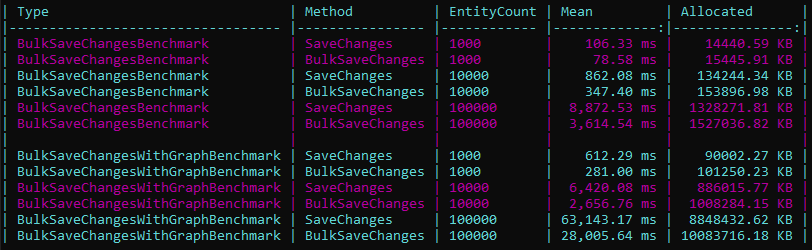
There is also a method that improves read performance by using a SQL JOIN instead of a large IN statement. I'll leave it to you to discover more about it here😊
You can further customize the behavior of these methods using the available bulk and column options.
And if your goal is to completely avoid loading data into the application context, you also have batch operations at your disposal.
Summary
If your application is data-intensive and requires significant performance gains, this library is a must-have.
With its seamless integration, you can add batch operations directly to your existing DbContext. This will deliver dramatic performance improvements while significantly reducing your application's memory footprint.